Yeah it is wobbling, I have had my first casualty.
3 Likes
Dead node? What was the cause?
It may be nodes filling if @josh you had a full one. It could become harderto actually get data into valid/close nodes at this point hmmmm
Cc @qi_ma it might be worth getting some client runs in now to see if we can see any fails
4 Likes
On the hoof but looks like mem.
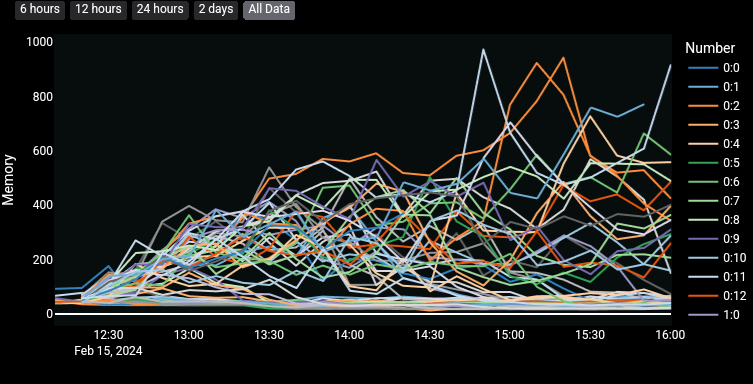
Odd thing, @aatonnomicc nodes are using way less RAM than mine. I pressume he is using the older node version. Could it be?
His are barely breaking above 100 I have many waay higher. 1 peaked at 1000.
@joshuef I am 2 down now.
2 Likes
At least for about an hour these nodes have given this same message (from CLI logs):
[2024-02-15T14:34:47.769580Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWB5WCpo229UNXDigwTjaGecP9kbxhmNomdBcjq7SEqRxq")
[2024-02-15T14:34:47.769603Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWBrQQJxnob8sbQ5yPvX7hHLG3y26ZY6J7TkSM4J9nQZUT")
[2024-02-15T14:34:47.769626Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWDxrxCm3b8cGzr6P86tjPoYxUwez2bcgkq2h1mKiBQA5V")
[2024-02-15T14:34:47.769648Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWHpRVLxu7MToRFgd8Wjxed5gFR2NkLhcWEiWrbCdnNxzt")
[2024-02-15T14:34:47.769669Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWRj4NsZFRTvV8SQP1bVF2bRqbQF3E7Ysqnu4MMKzh8Sb7")
1 Like
[2024-02-15T15:59:28.620334Z WARN sn_networking::replication_fetcher] Replication Fetcher doesn't have free capacity.
Currently has 5090 entries in queue.
What are entries in this context, chunks?
2 Likes
records.
it’s normal when having a new node just started up.
just need time to fetch from others then calm down.
5 Likes
Having a few files with “stuck” chunks, i.e. chunks that don’t upload, no matter how many retries, I can’t help myself asking:
what makes these chunk so different from any other chunks, that they just can’t be uploaded?
Is that a previous payment/cashnote?
Can that be ignored/reset, even if that involves additional payments (wich seems to happen anyway)?
I’d be more than happy to repay a certain amount to finish an upload with 1 “stuck” chunk out of 1400…
6 Likes
Post logs from your client when something like this happens. It can help devs find why is that happening.
2 Likes
Looks like all 100 nodes I started while ago finally caught with the network.
It took them 440GB download, 115 GB upload and almost 5 hours on 200/200 Mbit line.
4 Likes
This is easily reproducible and happened to people repeatedly in the past. In any case, here are the logs.
safe logs.zip (195.7 KB)
2 Likes
I wonder if my mem use vs @aatonnomicc is due to mine catching up and his are just cruising having started yesterday.
Edit: seems to be the case, it was just a big task catching up.
2 Likes
Not the cashnote. I tried to upload a different file, and checking the logs I find the same nodes malfunctioning again, after several hours:
On top of those five, there are many many more that give the same response. I’d say there is nothing wrong with the chunks, it’s in the nodes where these chunks try to land. Paging @qi_ma, @joshuef.
At least the nodes below mess things up. Maybe folks should see if they have one of those? I checked my own node against my recent upload log, and didn’t find it there.
Summary
[2024-02-15T18:46:56.120361Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWDEtwpaReKci1YJsoZTdYqktwsV55jnbbQsQWVusGPAs6")
[2024-02-15T18:46:56.120379Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWEjwp3nAAYCDBxAto1DVsfKYSFLDQzAkPRLR7zSQwj3XL")
[2024-02-15T18:46:56.120396Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWHayTN57nwfwH2jfCFucGEeDw4iv1TEVZhDgtqEv4BxTV")
[2024-02-15T18:46:56.120415Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWQrFnEuNwJBDfrcMTa5UF3VofEpdMnEcu2VtKWnvg8Tbs")
[2024-02-15T18:46:56.120432Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWSWiDERRwVDJztEue3SYoVKPMMzvh3noAjymo2gi26GGz")
[2024-02-15T18:46:55.105598Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWDj6DWTPJsBvUeH3q73xk1MWpLcjvSzAQXJUu2mNMCxKY")
[2024-02-15T18:46:55.105625Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWEWnVxCEyv42cAecZKVnsYyJnbTMmQQq8HjuABScqaLz2")
[2024-02-15T18:46:55.105649Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWEnuHjhNy2DujFUTEni2qiqEK1nkY1FL44HwyuPU16QQK")
[2024-02-15T18:46:55.105675Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWK3784brbyho99xTKPFvdZh87VLkMkCuAbj9uREN3ZKMM")
[2024-02-15T18:46:55.105703Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWSrNmW8DYkCW6yjsJ3acMyiThAs2wRziJeu1sSDbyr7Gy")
[2024-02-15T18:46:55.052865Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWFh32t8jzLkHuK669rTSWJQNXDAWNjCBAdTtHSAbCMKhe")
[2024-02-15T18:46:55.052903Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWH5XiRZ6qdxVnC4zVP357xykFSXDVJJRKEvG4VofLroz3")
[2024-02-15T18:46:55.052937Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWLg5RHitWvzsqi3pvS1UuxmWLcuUQX6YPQLE4UKx6MY9f")
[2024-02-15T18:46:55.052972Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWMMfECUFcJR3n8YQY9yutngYEvMaPyELEg8UQgLYtaBdb")
[2024-02-15T18:46:55.053005Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWPQxMe9VXZvszMQaKY5QtETqE61jaW2MnBxvEM4curMWp")
[2024-02-15T18:46:54.822676Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWFPGy1Y7CtZnzAKowgdVbN9NHRDRMF2EhbYGjnGnap7PW")
[2024-02-15T18:46:54.822686Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWMuS7ESVCVWwJKHUwMPYXVB6Vr2uu4CbgbK1HrLnggnH6")
[2024-02-15T18:46:54.822694Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWSQ3R8nnGDgpMssboJP4PDJEjhQkZqvn1yCPW7fCqRXhF")
[2024-02-15T18:46:54.822703Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWSQbQmbrsmHTfGNhoTUQ3v4pLM7wwKhBPP5fRNPtDVSh3")
[2024-02-15T18:46:54.822712Z DEBUG sn_networking] Did not get a valid response for the ChunkProof from PeerId("12D3KooWSj5WfWsUNJPV9ZPpNuZ7YhLadMAjhAoJwjVU48YuuBB9")
Actually there seems to be so many of them, that I bet they are either Maidsafe’s own nodes, or run by some community member who has many nodes.
3 Likes
Do you see IP addresses of those nodes? It could be one computer with some problem.
My nodes which know nodes from the list also cannot talk with them. Here is an example:
grep 12D3KooWDEtwpaReKci1YJsoZTdYqktwsV55jnbbQsQWVusGPAs6 safenode.log
[2024-02-15T17:26:54.805965Z ERROR sn_networking::event] GetClosest Query task QueryId(8290) errored with Timeout { key: [0, 32, 204, 134, 55, 195, 161, 223, 12, 43, 87, 60, 173, 46, 127, 202, 54, 237, 189, 161, 216, 18, 232, 101, 11, 136, 13, 250, 137, 7, 113, 79, 128, 12], peers: [PeerId("12D3KooWEjwp3nAAYCDBxAto1DVsfKYSFLDQzAkPRLR7zSQwj3XL"), PeerId("12D3KooWSWiDERRwVDJztEue3SYoVKPMMzvh3noAjymo2gi26GGz"), PeerId("12D3KooWDEtwpaReKci1YJsoZTdYqktwsV55jnbbQsQWVusGPAs6"), PeerId("12D3KooWQrFnEuNwJBDfrcMTa5UF3VofEpdMnEcu2VtKWnvg8Tbs"), PeerId("12D3KooWHayTN57nwfwH2jfCFucGEeDw4iv1TEVZhDgtqEv4BxTV")] }, QueryStats { requests: 47, success: 37, failure: 0, start: Some(Instant { tv_sec: 94387, tv_nsec: 150652002 }), end: Some(Instant { tv_sec: 94397, tv_nsec: 270255211 }) } - ProgressStep { count: 1, last: true }
1 Like
Unfortunately not. Seems that logs only contain IP’s of bootstrap peers.
After mey feeling too many nodes at once was not helping .
Iv been starting one node every 80 min on each machine. I picked 80 min as I wanted to spread all my nodes joining over 3 days. No reason for the numbers picked just thought I’d give it a try.
But definitely noticed when the release came out and people joined nodes quickly things went south.
7 Likes
I tried to upload a big file, about 4000 chunks, and about 40 of them land persistently so that all the 5 replicas are not available. Based on the calculations on this thread, that should mean that quite a big number of nodes are dysfunctional. I cannot calculate the exact probabilities, but I’d say between 20% - 40% of nodes.
It’s a pitty that we don’t have a way to kick those nodes out of the network.
8 Likes
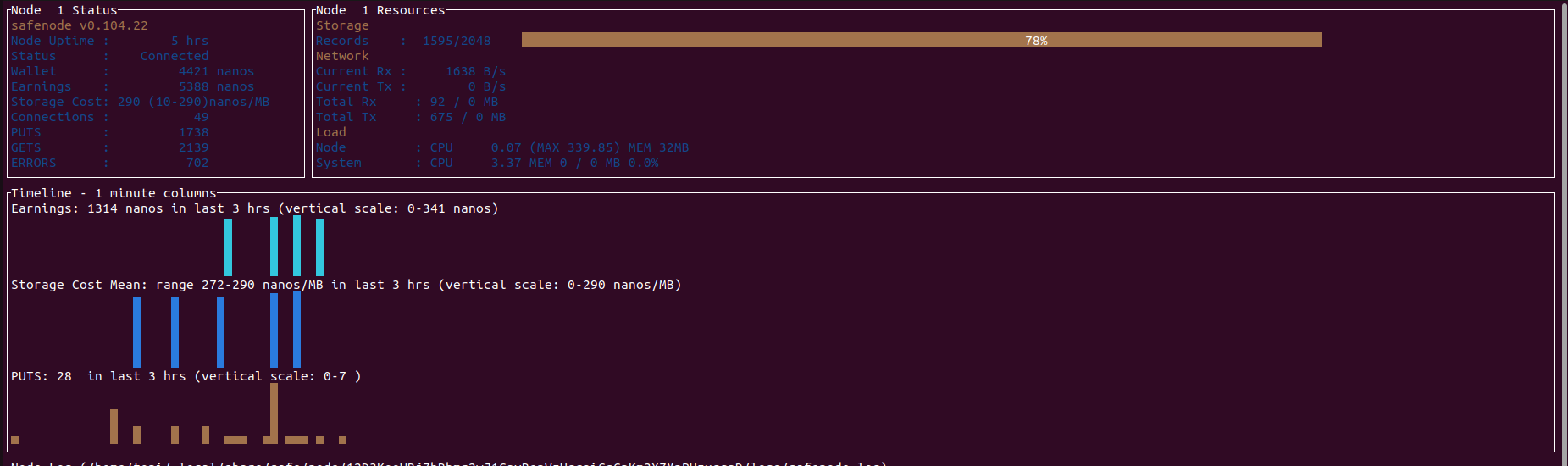
Looking at my node in Vdash, it seems that after initial activity it doesn’t do much, even though it is connected. The end of things going on may or may not coincide with a time when I had to reboot my router.
1 Like
I wasn’t suggesting there’s (necessarily) something wrong with the chunk. But it might not be dysfunctional nodes either. Since we had this problem for a while, my guess is that is a consequence of the non-deterministic nature of the network (churn/replicatin/latency/oth or combination of those factors)
Either way, my question was why not “resetting” whatever that chunk condition is (was it promised to a specific node?) until succesfully uploaded
Until today around noon, when most of the nodes were those of Maidsafe, the uploads had worked perfectly with great speed and without the typical slow chunks that destroy the user experience.
One of the problems could be that a network with too many new nodes in a short period of time generates so much data relocation that the whole system suffers.
Perhaps the idea of so many nodes running on the same computer will end up being detrimental to the network and reducing their number somewhat is the best way to go.
3 Likes
It seems to me the main problem are unreachable nodes that are not being kicked out and then connection timeouts make the network slow and bring other problems.
7 Likes