All you need to do is just extract the archive you already downloaded earlier.
1 Like
Sadly, I may have caused him to wipe his home folder, in which case he might not be back for a while. ![]()
1 Like
![]()
I’m sure he’ll be fine.
1 Like
For Sale: Smashed Mac with brand new hard drive. ![]()
1 Like
Yeah, he’s not back … he’s either reinstalling his OS or prepping to murder me.
:GUILT: ![]()
![]()
1 Like
Hahaha
Just had to put a pause on the tinkering. I’ll be back at it tomorrow.
5 Likes
Thank god. I was writing my will. ![]()
Make sure to remove the line 108 if you run that script.
3 Likes
So great to see everyone’s analysis here and info on nodes’ health ![]()
I can report that we have lost nodes too. I presume to the same spike. It may well have been a cascading situation that then stabilized.
We’re at 1675 nodes, and some of those are at capacity now. I’ll be poking about to see what I can see of those nodes today. (will update OP too).
Edit: initial analysis shows this was most likely replication related. There’s a lot going on in nodes that died.
Mem was ~340mb at the time. (So not insane, but if we can smooth that out that’ll be good).
We did discover a couple of replication-related bugs in the last week. I’m not sure if that’d have impacted this.
We may just be too keenly replicating, and need to turn that down / make it configurable based upon the system.
I’ll update more as we poke more at this!
26 Likes
Failed to setup SSH before coming to the office and now have to wait another 8 hours to get back to tinkering.
3 Likes
My periodic (hourly) upload has started failing with this.
🔗 Connected to the Network Preparing (chunking) files at '2.2MB.txt'...
Making payment for 6 Chunks that belong to 1 file/s.
Error: Failed to send tokens due to Network Error Could not retrieve the record after storing it: Key(b"\x07v\x01\x83h\xc5\xd5\x17\xe8`j\xd7\x82$z\x85\xe9\xdb\xd3whA\xe4\xac\x06\xaf\xd2\x0c\xcb\x1c\x98\xc2").
Location:
sn_cli/src/subcommands/wallet.rs:293:18
12.72user 3.19system 0:58.45elapsed 27%CPU (0avgtext+0avgdata 58076maxresident)k
0inputs+5128outputs (0major+51897minor)pagefaults 0swaps
Status: Upload successful
7.52user 1.46system 0:48.77elapsed 18%CPU (0avgtext+0avgdata 33744maxresident)k
0inputs+4288outputs (0major+19734minor)pagefaults 0swaps
Status: Download successful
Command exited with non-zero status 1
7.31user 0.90system 0:56.08elapsed 14%CPU (0avgtext+0avgdata 33912maxresident)k
0inputs+4464outputs (0major+13144minor)pagefaults 0swaps
Status: Upload failed
7.40user 1.58system 0:51.19elapsed 17%CPU (0avgtext+0avgdata 32948maxresident)k
0inputs+4296outputs (0major+16794minor)pagefaults 0swaps
Status: Download successful
Command exited with non-zero status 1
8.19user 1.06system 1:00.11elapsed 15%CPU (0avgtext+0avgdata 34908maxresident)k
0inputs+4464outputs (0major+14363minor)pagefaults 0swaps
Status: Upload failed
7.22user 1.55system 0:43.06elapsed 20%CPU (0avgtext+0avgdata 35624maxresident)k
0inputs+4288outputs (0major+18314minor)pagefaults 0swaps
Status: Download successful
Command exited with non-zero status 1
7.59user 1.03system 1:02.65elapsed 13%CPU (0avgtext+0avgdata 33476maxresident)k
0inputs+4464outputs (0major+13767minor)pagefaults 0swaps
Status: Upload failed
6.88user 1.45system 0:45.00elapsed 18%CPU (0avgtext+0avgdata 33472maxresident)k
0inputs+4288outputs (0major+19317minor)pagefaults 0swaps
Status: Download successful
Command exited with non-zero status 1
10.08user 1.46system 1:16.40elapsed 15%CPU (0avgtext+0avgdata 38668maxresident)k
0inputs+4464outputs (0major+15674minor)pagefaults 0swaps
Status: Upload failed
7.09user 1.52system 0:46.74elapsed 18%CPU (0avgtext+0avgdata 34016maxresident)k
0inputs+4288outputs (0major+15790minor)pagefaults 0swaps
Status: Download successful
Command exited with non-zero status 1
8.24user 0.89system 0:54.01elapsed 16%CPU (0avgtext+0avgdata 34100maxresident)k
0inputs+4464outputs (0major+13485minor)pagefaults 0swaps
Status: Upload failed
6.83user 1.32system 0:44.29elapsed 18%CPU (0avgtext+0avgdata 35552maxresident)k
0inputs+4288outputs (0major+17243minor)pagefaults 0swaps
Status: Download successful
10 Likes
Is that uploading the same thing each time?
1 Like
No, but it does have the same name each time.
For the download I upload a file once and then time the downloads of that specific file.
For the upload it is a randomly generated 2.2MB file but always the same name.
I was not certain if uploading the same file repeatedly is equal to a uploading unique files.
Is the name causing the issue?
Only around 100 uploads, I would imagine many thousands of unique cat pics being named cat.jpeg ![]()
(Although I was wondering if this was the cause)
2 Likes
It should not be. Do the commands have any delay between them or it’s all back to back?
It could be that the upload isn’t 100% successful, but that doesn’t mean that all data isn’t on 7/8 nodes… But that should mean that the upload does not fail on validation… which is what it looks like at the moment. ![]()
1 Like
The upload is on the hour and download 30 minutes later.
As in each command runs once per hour but 30 minutes apart from each other.
1 Like
Magic ![]()
![]() it started working again.
it started working again.
It appears the issue was with the network as I made no changes on my end, came to add a counter to the name just in case but found the issue went away.
Great that it sorted the problem out and carries on!

10 Likes
I’m slightly baffled by this! My AWS Instance had lost more nodes and I was down to 31 from the initial 50. So I killed them all and started a new 50.
Look at how the, Network in (bytes) and Network out (bytes) have changed.
I’m getting records so I’m not surprised that I’m getting a lot of Network In. But why the relative lack of Network out (bytes).
Also, look at the difference between Network out (bytes) and Packets out (bytes). Are the new nodes doing a different kind of traffic?

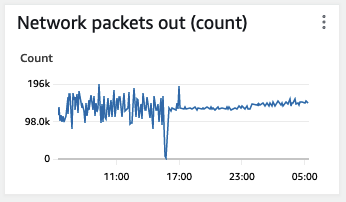


3 Likes
are the new nodes the same safenode version?
1 Like
Yes, no upgrade in between. Just killed the old ones and started new ones.
Edit: This is the version:-
safenode cli 0.87.1
1 Like
I think might have just answered my own question! Maybe…
Could it be that they are new nodes so are taking a greater share of new data coming into the system? Does the network do that?
That would explain the higher number of bytes coming in and the higher number of packets.
And maybe there aren’t as many bytes going out because there is less need for replication writing to other nodes due to churn for the records written because they are newer and therefore the nodes they were originally written to are still alive? I’m guessing that the older the record the more likely it is to be on nodes that are subject to dying.
Is there that kind of interaction going on?
2 Likes
They’d be new and therefore getting a lot of data coming in in terms of data packets that already exist that they should be responsible for.
Yeh, as they’re new they dont have any data to send anywhere unless requests come in or until there’s more churn ![]()
Is there that kind of interaction going on?
I suspect that might be it. lets see if they quieten down after replication is done.
3 Likes