Announcement: Latest Release
Please follow these instructions to upgrade your nodes to the newest version to ensure the best performance and stability for everyone! Check out the Github Release with changelog details
Then, press Ctrl + U, and hit Enter. This will upgrade your nodes. Upgrading can take several minutes for each node. Please don’t close the app or stop your nodes during this process.
Your nodes will now stop
Press Ctrl + S to start your nodes again
For CLI Tool Users:
If you’re using the CLI tool, please update and upgrade. Run the update first: antup update
Then run the upgrade: antctl upgrade --interval 60000
Finally, start them again with antctl start --interval 60000
For ALL Users:
Please start your nodes gradually — especially if you plan on running multiple nodes.
Be conservative with CPU allocation to maintain stability
You must be on 2025.7.1.1 or newer to earn rewards
Nodes with proper port forwarding configurations can now earn rewards as expected, this version addresses prior earning issues affecting those nodes. Please avoid --relay as it is very unhealthy from the network and no longer gives any earning benefit.
NOTE: this observation may be because the network as a whole needs to upgrade to remove the behaviour, so this is an observation by an early “in place” upgrader.
Still seeing the quasi split, not network split but more of a routing split where one portion of the network talks to each other and sometimes breaks through to the other portion. And visa versa
Think of the highway/motorway, its singular but with parts, and you can only get to the other side occasionally. Maybe not quick enough before timeout. So the network is not split, but more of islands where its harder to get to the other islands than on your own island.
This is evidenced by the start phase of the nodes and some see a smaller network and grab a wider range of records, and other nodes see a larger network and grab the “normal” number of records to store (well they were there from before).
Well the internal test networks quite possibly do not use port forwarding. That is unneeded for VPS since there is no router and port-forwarding doesn’t exist for those nodes.
It did show up but was accidentally overlooked. Going forward, we have made changes to the reporting tool to ensure this is caught or at least highlighted as an issue, when certain metrics show up 0. Many components of a full cone nat setup were working properly with their other peers & nodes in a testnet internally except some metrics were 0 (very few), which is where the issue actually originally surfaced.
This is not true.
We do emulate NAT conditions outside of simply getting assigned public IPs on DO:
symmetric nat (used to emulate --relay mode (soon to be removed I believe))
full cone nat (in this case equivalent of port forwarding if on full cone NAT at home setup)
port restricted cone nat (POC done but not live yet internally)
All these NAT emulation modes have their own gateway/router setup on DO droplet along with a private droplet (LAN IP CIDRs) communicating with its external respective gateway.
Used to think running nodes from all sort of connections from home was a priority, but this looks like a distraction until the most basic functions of the network is rock solid.
Some nearly 12 hours later and the first machine I upgraded “in place”, that is upgraded the nodes one by one by stopping the node and restarting with updated binary, is still seeing huge numbers of records stored for each node. Like 13,000 records for 250 nodes.
I will try restarting manually one by one, but forcing a reset so it gets a new ID and see if the same behaviour results or like last time has a more “normal” value of just a few records max. (not talking of responsible records here)
I have a continuous downloader running on a set of files with a large range in size.
The download situation will not be restored until most of the network upgrades. At the moment our monitoring shows only 20% have upgraded. So the vast majority of the nodes at the moment still have the external address manager removed.
As per ~10AM BST, our monitoring also reports a very large dip in the number of nodes. Not sure if this is someone who has pulled out or is intending to upgrade. Qi does not think the reduction is due to a technical issue.
If progress remains slow on the upgrade, perhaps it will be considered. We wanted to give people a bit of time and play it a bit safer with the amount of churn. On the last release we got people complaining about it being too restrictive.
Well it is one obvious symptom that can be reproduced and capable to be bypassed, although the bypass weakens the network a bit.
Yea, it points to some issue in how the nodes are viewing the network and seeing themselves in a less populated region of xor space, and that then points to an issue arising in routing. That then leads to issues in uploading and downloading and actually finding the data quick enough without timeouts/errors
It is also something that relay nodes do not see.
There is something not correct within the node’s routing and only introduced with V 0.4.2
It is a marked difference and there is no reason for a node to think its close neighbourhood is a much larger range of XOR addresses from version 0.4.1 to 0.4.2/0.4.3
Personally I feel they are missing a key factor to point them to one of the problems.
EDIT: Read further on that only 20% of the network has upgraded, so guess it could still be a left over from the 0.4.2 version and was already fixed in the 0.4.3 version. And not seeing the fix since the 80% of 0.4.2 nodes are “hiding” in the shadows of routing causing the effect/problem.
That was my sleep time here. Last night before bed all my nodes were upgraded (one node at a time) and working great, except the record stored count. But just now I checked on them and its not looking good Jan.
Also may explain the "very large dip in the number of nodes".
Many of my nodes do not see a large network at all, many nodes on a couple of SBCs have dropped out of talking to anyone.
These are port forwarded nodes, work well since launch in Feb and in beta, so I see no reason to fault the setup or capability of the machines/internet.
If I force a restart on a node it returns to working state,
But this could be the reason for that large drop if this is happening to others. My 750 node setup is not going to be noticed.
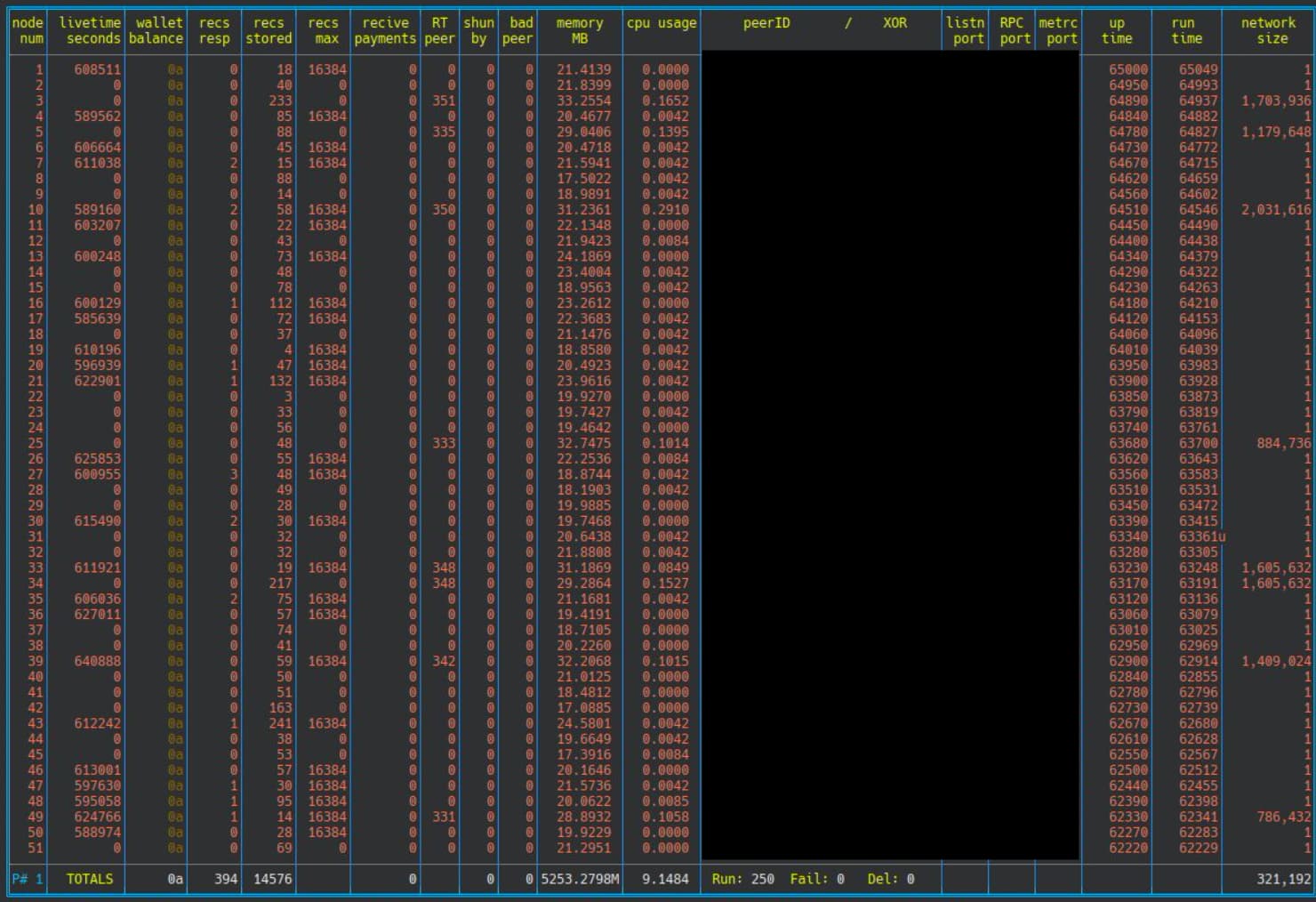
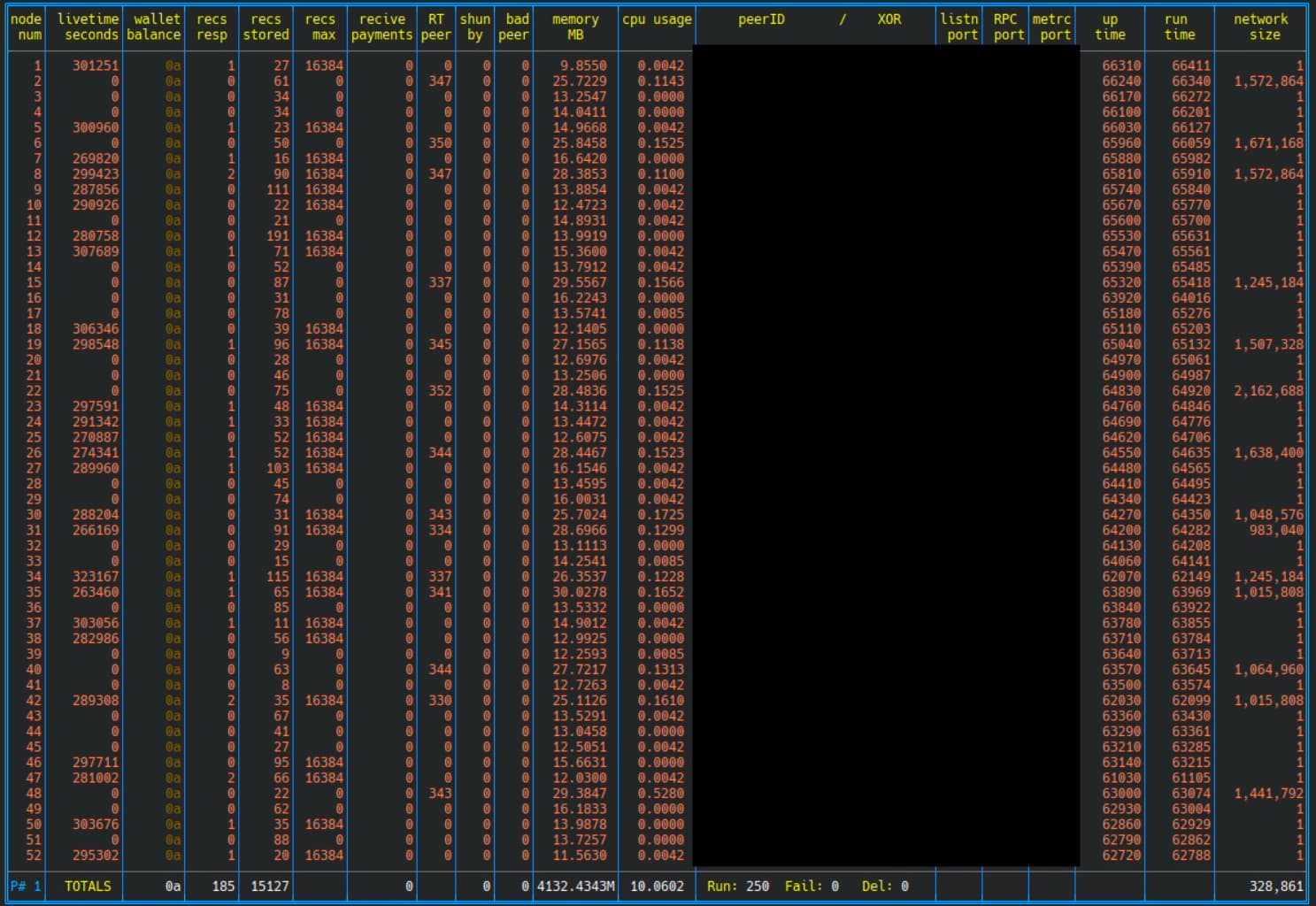
Here are screen shots of the status of the first 50 nodes on each machine. Note that if “livetime” and maybe “recs resp” have a value then the node will have been requested a quote from it at some time in the past. Some of the non responsive nodes show they have at some time been a part of the network as asked to give a quote.
Also note that for SBC2 the nodes are still connected to the network but have wildly different values for network size ranging from very small to close to the network size most nodes see. And from the average size over the whole 250 nodes on the SBC we see the network appears very small.
This setup has worked for a nigh a year. The port forward has had no issues until the v0.4.2 emissions issues, but otherwise no issues.
I was using --relay on one SBC for a couple of days there. But was back to port forward before upgrade to v0.4.3 and one SBC (sbc3) had not been used for 2 weeks and upgrade to node done before starting it afresh.
The point of the screen shots was to illustrate a potential reason for the big dip in numbers seen by the team