I cannot say for the version from last week since I didn’t use vdash on it. But the 2nd previous version definitely was reporting bad to the considered bad node
vdash definitely showed a bad node message arriving either shortly before or during the update last night, and after every update.
So I don’t see how it can be due to very old code. My nodes are always updated right away and have always had bad node reports afterwards.
I’d have noticed if this had stopped after an update, and when others post vdash screenshots - they always indicate some bad node reports, which show as “Shunned” count on the right edge of the status summary.
@roland so probably those messages were making it through when you thought the channel was closed, and that may indicate a bug.
EDIT: thinking again it’s possible that the previous version (to last night’s update) did reduce or stop shunning. I did think there was at least some in that period but it was much higher prior to that, so it might even have dropped to none.
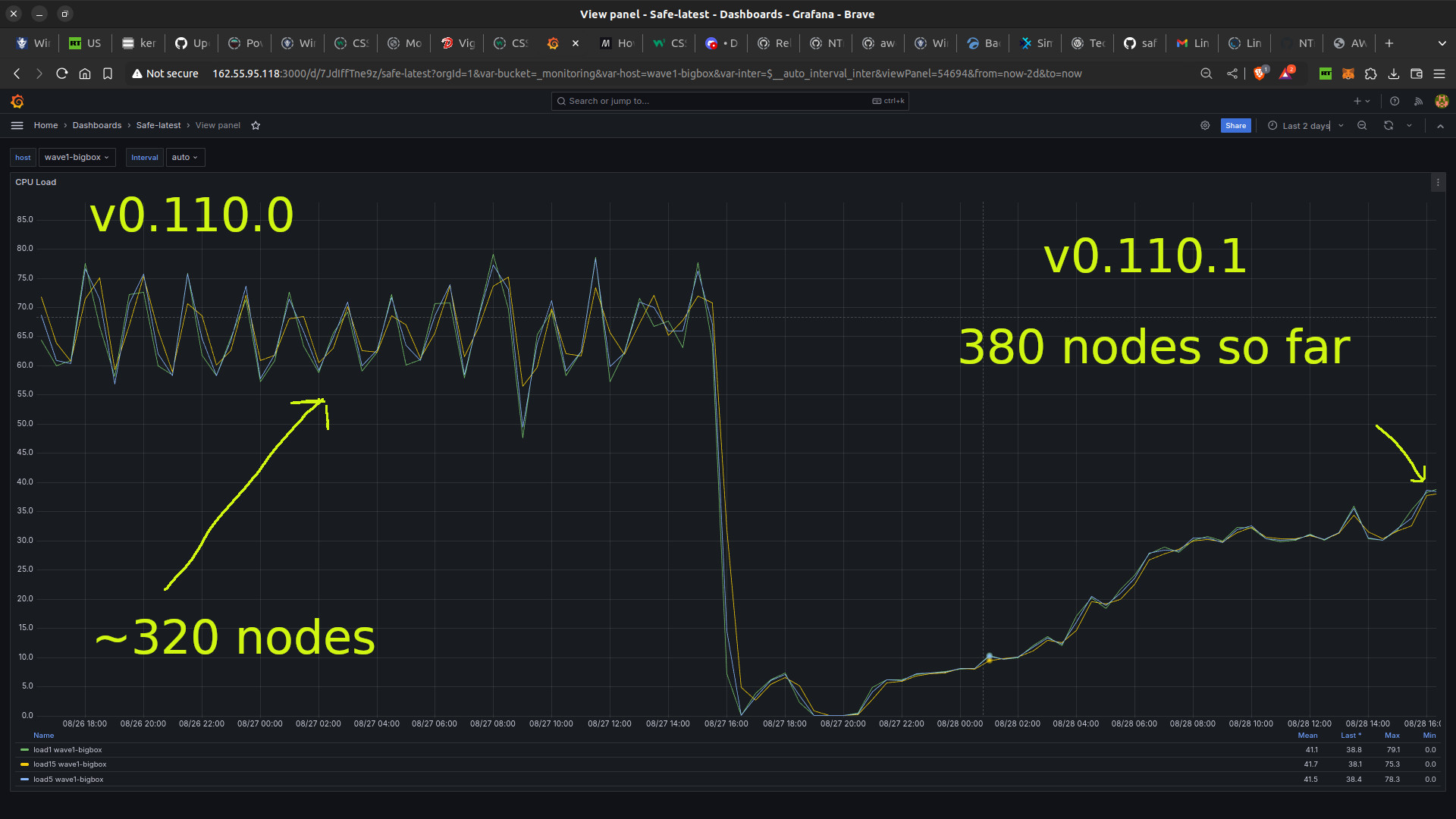
Im hopeful I can get >500 nodes on this before the load avg goes exponential as it did previously when I tried to run >350 nodes.
Special mention to @aatonnomicc and his anms.sh script which is only starting nodes when the load avg is within safe parameters.
FWIW here is my /var/safenode-manager/config
safe@wave1-bigbox:~$ less /var/safenode-manager/config
# edit this file to confrol behavior of the script
DiscordUsername="--owner southside_the_magnificent"
#DiscordUsername=""
MaxLoadAverageAllowed=50
DesiredLoadAverage=40.0
CpuLessThan=85
MemLessThan=95
HDLessThan=95
# counters start at this number and upon action happening
# increment down once every time script runs when zero action is allowed again
# for systems 24 and over cores there is a seperate value calculate
DelayStart=2
DelayReStart=10
DelayUpgrade=5
DelayRemove=300
NodeCap=500
UpgradeHour=1
UpgradeMin=3
NodeVersion=""
This will start a new node every 60 seconds up to a max of 500 IF all are true
Max loadavg1 is =<50
CpuLessThan=85
MemLessThan=95
HDLessThan=95
I wonder what is the bottleneck when we try to run a lot of nodes on single machine. I have currently 200 nodes running fine on 8core 15W CPU, comparing just raw power 24core server CPU should be able to run 1000 nodes or more.
Maybe memory latency or throughput is the problem with many nodes…or many active processes means lot of CPU time lost switching contexts, clearing caches etc. There is definitely a lot of space for research and optimizations somewhere.
i know it’s pretty late in the game … but the token being collected by the bot come with metadata - right? afaik it’s just the owner that is being sent with the coin for now …
…but couldn’t they send in a lot of other valuable data too?
system service/user service
OS
number of nodes on system
number of cpus/ram/hdd size
loadavg
maybe loopback-time of some kind to measure the responsiveness of a node …
obviously this would be a skewed statistic because it would only include nodes that do earn and not nodes that don’t … but it might show what kind of nodes people run that are ‘making money’ and if the incentives are being set right …
edit: (…theoretically that metadata could be included in royalty payments even after network launch …)