Running one node (IronAnt ![]() ) on windows 10 latop (giffgaff mobile)
) on windows 10 latop (giffgaff mobile)
***node is running ,all my other apps, services are running smooth,
happy days, ironwolf is cool haha *****
Running one node (IronAnt ![]() ) on windows 10 latop (giffgaff mobile)
) on windows 10 latop (giffgaff mobile)
***node is running ,all my other apps, services are running smooth,
happy days, ironwolf is cool haha *****
Shunning is still pretty epic for me.
One might say I have more shuns than nanos on way less nodes.
Leaderboard for most shunned perhaps?
This mirrors my experience too. Some nodes are close to my total nanos (100 node) over 30 shuns on a number of nodes
The 4MB chunks really hammers the network (autonomi, and ethernet/internet) and stresses too many node setups. The number of bad nodes out there reported by my nodes is through the roof
I checked in thinking that I might up my node count as I am only running 60% of what I had in test 1 with no problems.
That’s a no can do, possibly may need to restart at even less.
Are you folks over subscribing your nodes in regards to not having adequate bandwidth, cpu, memory (higher requirements for this testnet), and session tables (capacity) on the routers, or all that is all healthy and has some buffer room ?
Our nodes are no where near 30 shunned counts on average. Its less than 5.
Additional note: More uploaders were brought online (doubling every 4 hours so far), but we will pause on bringing more uploader capacity online for a little bit (possibly over weekend), before resuming a further aggressive upload rate.
Our nodes continue to look stable, and upload speeds are holding very steady as additional uploaders were brought online (no sign of aggressive slowdown with time consumed on uploading per uploader’s payload on the current fluctuating network size thus far).
I am running mine on dedicated servers, the home rig is out of commission.
CPU ~34%
RAM ~28%
Gig symmetrical
Shuns anything between 4 and 14 per node.
As mentioned above running 40% less nodes that test 1.
I only started enough nodes to use my bandwidth.
I can only run about 1/2 the nodes from the 1/2MB chunk sized networks
I was getting issues with only 20 nodes but b/w fine once settled down
I can run 100 nodes now instead of nearly 200 for 1/2MB chunk size
This pattern of shuns and detecting bad nodes out there started from the start when no uploads were happening, uploads doesn’t seem to have changed the rate much
Nodes are running on 24 core cpu with 256GB RAM and many TB of disk
And my observations is that 4MB chunk size hammers home internet connections that are not optimised networks that DO have at 1Gb/s to 10Gb/s connections
And I will get my eye poked out with so many I
Yea on DO I would expect that, matches with my analysis
I don’t think it was a numbers game to run as many safenodes as one can pack inside a single host for any person in general, and that be the only metric to gauge against, and that it must increase on every testnet etc. We need to strike a balance on a lot of different angles here.
It sometimes feels like folks gauge based on two things (generally), receiving nanos and how many safenodes one can pack inside their same hardware, in between different testnets for maximum safenodes possible, ![]() .
.
There is more to it than that, and I am sure you and a lot of advanced safenode users agree there, ![]() .
.
Anyhow, just to reiterate this a testnet experiment at 4MB chunk size and its not sort of any final decision at this stage.
Sure, I was only stating an observation from our end as a general update here.
Also, looking forward to when things get heated up with way more uploaders over the next few days, ![]() . Cheers!
. Cheers!
I have a question, do we know what the effect is on end users with normal home routers, who until now could run 1-2 nodes because of the too many connections opened in the nat table?
I would guess that the current nodes are taking more advantage of their available internet speeds and if so I’m ok with power users suffering because they are not mainstream…
Check out the Dev Forum
I wasn’t playing a game, but noting that 4MB chunks are much harder on b/w requirements.
200 nodes did not max out the bandwidth, but 100 does.
Translated, it means that machines/internet connections that could only handle 2 or 3 nodes may end up not being able to run even one node. And if they try then increase instability across the network.
The number of shuns and bad nodes speaks volumes about network/node instability. DO nodes work great but the network out there is not
The network success is not how many nanos you get or maximising storage on one machine. It is about getting the maximum number of people running nodes to create the decentralised network. No good if nodes can only run on data centre machines (extreme case). And obviously there is a balance between max people and overall performance (acceptable storage on network, speed to store and retrieve data, and so on)
Its all good. I know you have re-iterated your concern(s) and analysis here about the 4MB and its not being ignored.
Still very much a live experiment testnet. We are continuing to observe and analyze.
Fwiw, the success rates’ for users attempting to relay through at least through our nodes is still above 90%. This is for users who can’t port forward or do UPnP.
Just to add to this,
CPU ~34%
RAM ~28%
Gig symmetrical
I have not even remotely stressed my connection,
I don’t see why considering the above I am getting shunned as badly as I am.
This might be a retarded question but is there any chance that other peoples nodes who are struggling, mistakenly think that the problem is the node that they are reaching out to?
Coming to think about it a bit more any couple will know the reality of this problem.
Honey you are an idiot, no love you are the idiot… ![]()
Have you checked to see if it’s a “max concurrent connections” issue? Also, if I’m not mistaken, a lot more RAM is utilized on startup than after the connection has stabilized. Maybe it was a RAM problem on startup even though current RAM seems okay?
Ill go back in history later today if I have time, I can’t give you a definitive answer on that but I can say that I started with a 6 minute interval and before uploads got going so my immediate hunch is no but definitely worth a look.
Most of the shunned and bad peers count values rose for us in the first few hours off going live compared to the present values now (before uploaders started), since then its a very slow increase…
Yes, the number of connections also peaked for us including more RAM usage at the beginning, and since then it has fallen and remained steady. There is also the 100 max record cache size that has to get populated with records, which also increases baseline memory at startup.
Note: If at any point the CPU did hit 100% , you would have likely triggered shunned and bad peers counts to increase rapidly, even if it was for say 5 to 30 minutes at initial go live time period. It be good to verify you were never at that upper limit (looking back at your history), even with a 6 minute interval just to rule this scenario out.
FYI: I launched 10 nodes at a time on a gigabit (up and down) internet connection. Shunned nodes are less than 1%. RAM usage per node is now about 250MB per node. I’m allotting twice that for the startup surge when I estimate max nodes possible based on RAM usage.
Also, I’m using Launchpad and port forwarding on Windows 10.
There are now 100 uploaders running against the network.
In 8 hours time we will scale it up again to 150.
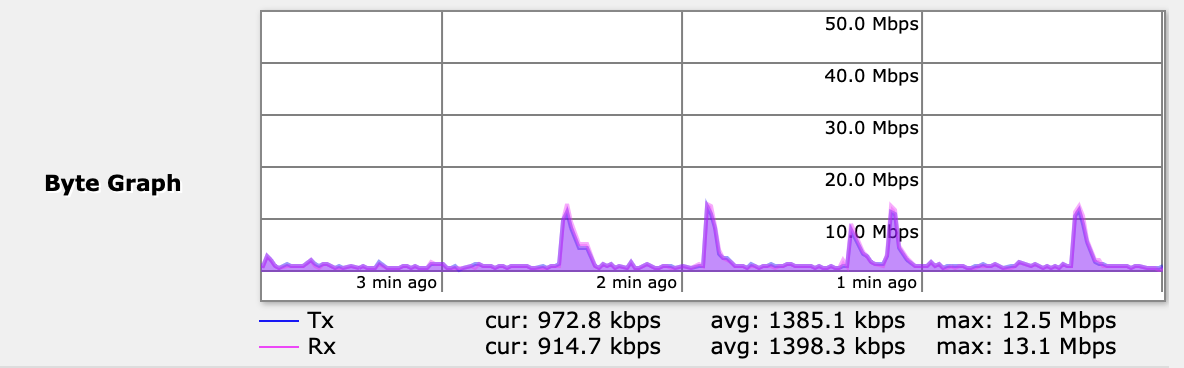
I can only really sensibly run 5 nodes on my 80/20 Mb/s ADSL. The issue isn’t the connections which hover around 1500 to 3000 but the peaks in send and receive. That’s what causes issues for other internet usage in the house.
On this graph
Tx = Router > Pi4
Rx = Pi4 > Router
It’s those big peaks that cause the issues. The peaks were less pronounced before.
The Pi4 would be able to comfortably have 10 or 15 nodes. No issues with the 8GB RAM or CPU.
And the 35GB per node is fully available. No under resourcing here.
So in theory I’m providing 5 x 32GB = 160GB to the network whereas it was only 10 x 2GB = 20GB before but that’s meaningless until it is fuller.
The number of shuns per node are 10, 9, 4, 7, 5 (I staggered the startup over an hour to be sure they were stable) so 35 in total in 2 days.
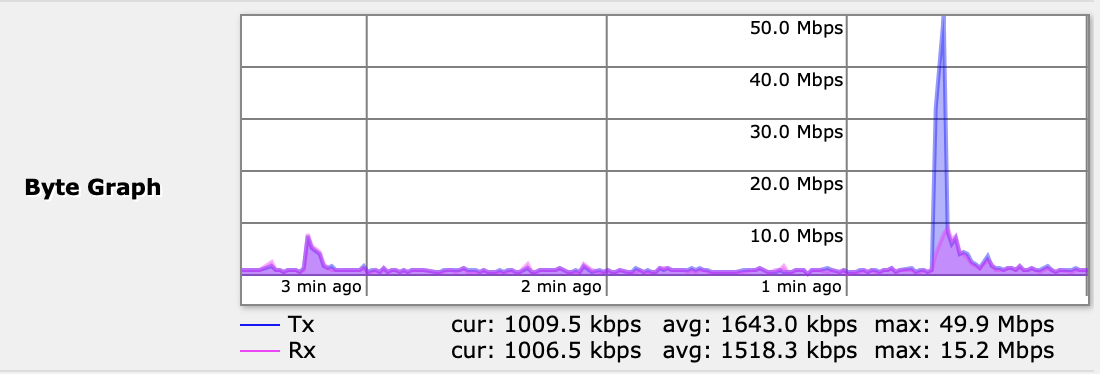
Edit
Even better graph. This was just 1 node going bananas
Thanks for that extra info. I appreciate it. There is more variables at play here than just 4MB chunk at the moment (not discounting that 4MB is obviously a larger payload than 512KB coming in) to your Pi from your router etc.
We have increased uploaders (and this is the most we have ever had running in any testnet), and the network size has stayed roughly the same for the past few hours.
I would think this would imply more network activity in general per safenode pid over the same time period (all else equal), which would mean more bandwidth used, specifically for PUT (spikes) if churn is minimal.
Number of Spikes vs Size of Spike would be tied to the number of chunks received and chunk size, as well in general ongoing replication due to churn of other nodes (ongoing).
If you had double the nodes due to say a 512KB chunk size, and everyone still had same physical resources in play at the current 110K network size, but instead the network size now magically was 220K nodes, the size of the uploads at the source per file aren’t changing (it would be generating more chunks for the same upload content).
Would you not be receiving just more chunks at 512KB in same time duration, all else equal (owning same % of nodes at the 220K network size), and then added up the incoming bandwidth for multiple chunks off 512KB over your 2x more safenode pids, would be much higher than the average baseline from your router’s perspective (i.e your 80/20 ADSL bandwidth) (same scenario as the 4MB if the timings off those chunks aligned on the receiving end) ? ![]() .
.
If I am incorrect in the above, feel free to correct me.
I do need to get some coffee this morning, ![]()