Based on the tight genealogy records of Iceland and with a mere 10.000 DNA sequences, we can now predict genetic defects of all 300.000 Icelandii. It is not going to take many years before a this ability spreads to all countries and all people.
It is my prediction that MaidSafe’s single most crucial data type will be a human DNA sequence. MaidSafe needs to launch now, so that it can be common place, and the only place where anyone wants to store their DNA sequence.
Shit, I thought it’s “Icelandians” or “Icelandese”. You spoiled my day.
If want to have your genes sequenced, you’d probably want to store them somewhere.
But why would I want to do that? I can’t afford any expensive treatments and by doing that I’d only increase the risk of my data loss (let alone the possibility that the sequencing service may “help me” make a backup of my data).
I’ve heard some ideas around this (from the bitcoin perspective, how one could allow access to certain records to certain addresses (i.e. certain users like hospitals, etc.) based on their request). At the same time that would narrow down the list of suspects in case of data leaks.
Wow, that sounds great, a new sharing economy
I’m going to check out that thread now, sounds really interesting - thinking of joining the "Post Capitalist crowd.
Thanks for the thread heads up
To be the next Internet, genomics needs its “light bulb moment” – the singularity where the technology reaches the point where applications can be built and deployed to the mainstream market leveraging the infrastructure built for and by previous applications.
I am all for leveraging the knowledge we can get from the upcoming revolution of massive genome sequencing. My concern is that it has to be done right: the people should collectively own this dataset, and collectively share responsibility for it. If we let slip this dataset into the control of a (few) single private corporation(s), then the consequences will be even more dire than they are currently for economic/financial data, or social data, or marketing profile data - read credit agencies and banks, Facebook and Google+anonymous web trackers.
This genomic database touches an immutable part of our humanity. I can become poor or rich, talk privately to my friends, or put up protections against being tracked online. I cannot change my DNA.
Imagine a society where on the day a child is born, a private company knows whether you will be likely to have certain types of cancer later on in life, or whether you will be susceptible to anger management issues. Or whether you will be above average skilled in a particular area. A private company with a financial interest can not posses such knowledge over children and adults without consent, and even without the human or the parents knowing this knowledge!
A centralized authority having access to every piece of information about you from the moment you are born until you die is a very real threat. It is thought that is the very reason the US federal government is spending so much money (600 billion dollar investment thus far) on developing electronic health records. They have already done it for a complete database on all children in public school.
I don’t even want to know what would happen if our DNA sequences were centralized and connected us too our identity. Having a secure non-human trusting place to share health information is needed. Project SAFE seems like the only reasonable option out there.
One discovery I have come across while researching integrating VistA with SAFE. The pic of the amount of data storage these researchers need is mined blowing. The thread discussion I found this in goes on to discuss privacy and security…this was four years ago
My intent is to upload the various file formats for genomic data as defined by the HL7 (Health Systems 7) Clinical Genomics working group, but I am too dumb to figure out how to load documents on the OSEHRA site - I will start by initiating a discussion.
Clinical practitioners can now interactively produce and query a patient report for genetic tests spanning over 2000 inherited diseases from a single whole-genome sequence, using www.genetests.org (Home - NIH Genetic Testing Registry (GTR) - NCBI) as a valid guide.
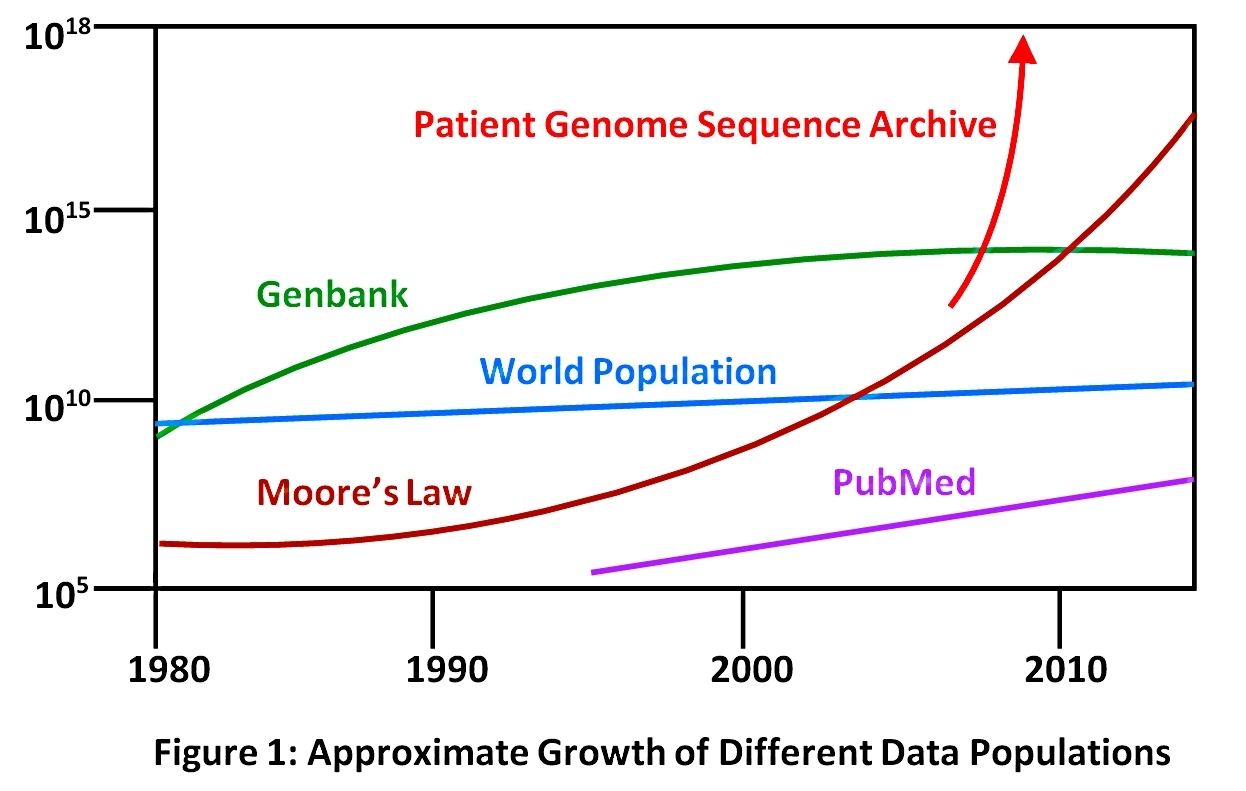
The amount of human genomic data is accumulating at an unprecedented rate (see Figure 1 below). For example, the BGI at Shenzhen, China has now installed over two exabyte (2 billion gigabytes) of storage to house DNA sequencing data. The institute will use the storage infrastructure to unify its 250 next generation sequencers onto a single shared pool of storage with a single file system. The BGI’s computing platform is greater than 1000 Teraflops, or one quadrillion floating point operations per second. BGI, as it is now known, is the world’s largest genome sequencing center. Its sequencing output is now more than 40,000 human genomes per year. Its key accomplishments have included the first de novo sequencing and assembly of various mammalian species including the human genome with short-read sequencing (so-called “next generation sequencing”) and the first sequencing of an ancient human genome. It has received over $1.5 B in collaborative U.S. funds from the China Bank.
The storage and access of different files containing patient genomic data represents a “Big Data” challenge, as was elaborated in PCAST NITRD “Big Data” Strategy Directive 12/2010:
“Data volumes are growing exponentially”
There are many reasons for this growth:
the creation of nearly all data today in digital form
a proliferation of sensors (e.g. Next-Generation Sequencing)
new data sources such as high-resolution imagery and video.
The collection, management, and analysis of data is a fast-growing concern of NIT research.
Automated analysis techniques such as data mining and machine learning facilitate.
Transformation of data into knowledge, and of knowledge into action.
“Every Federal agency needs to have a ‘big data’ strategy”
The next blogs in this sequence will define the Technical Requirements and routes for EHR integration of these massive patient-specific data records. Gerry Higgins, Ph.D.
I am a practicing physician assistant in Utah and also have a strong love for using technology to better the world. I have started a project that integrates open source projects VistA with the new decentralized, server-less, autonomous, anonymous network (SAFE; www.maidsafe.net) that will quickly replace all we know about the “internet.” In my research I have come across your OSEHRA group and postings with regard to the big data problem in genomics.
Your comments with regard to integrating genetic testing into electronic health records is brilliant, but likely an impossible feat with today’s broken system. Well with the advent of the SAFE network and the integration of VistA, it is absolute reality. The data storage capacity, cost, performance, and security is nothing short of revolutionary. My roadmap for VistA fork (HealthSAFE) is to get a working version going this year. The next step will be integrating in several wearable patient monitoring devices as well as using a person’s unique electrophysiological biomarker as the log-in method into the system.
Later phase is where I think our two passions will merge. My greatest hope is to return the caretaker role of personal health information to the patient. I think this will restore some of the faith in medical providers when we are able to abide by one of the first rules of the Hippocratic oath, ‘keep the information a secret.’ The genome of an individual seems to be one of the most sacred bits of information on the planet and really should not be totally intrusted (particularly identity associated) by anyone beyond the individual.
Long story short, I had a strong desire to pass on this information to you.