YOu may have 8 useful log files
look in ~/.safe/vault/baby-fleming-vaults/safe-vault-[genesis, 2-8]/safe-vault.log
YOu may have 8 useful log files
look in ~/.safe/vault/baby-fleming-vaults/safe-vault-[genesis, 2-8]/safe-vault.log
Logged then to https://github.com/maidsafe/safe-api/issues/443
and the file was this 2.3MB gif =

I started a network with 10 vaults instead of 8, and vaults 8 9 and 10 (ports 4007-4009) get into the endless loop of sending membership knowledge. So it would seem that vaults 1-7 are ‘normal’ but after that something funky happens with the membership knowledge / gossip.
This is the looping portion of the log for the first vault, showing the lines that loop approx every one second:
TRACE 2020-03-10T11:13:24.338684651+11:00 [/usr/local/cargo/git/checkouts/routing-616e72cf40f12bc0/76713d9/src/states/common/base.rs:230] Elder(0a1d37..()) - try handle message 35a3..5853
TRACE 2020-03-10T11:13:24.341246652+11:00 [/usr/local/cargo/git/checkouts/routing-616e72cf40f12bc0/76713d9/src/states/elder/mod.rs:714] Elder(0a1d37..()) Got Message { src: Node(PublicId(name: 27a29d..)), dst: Direct, variant: MemberKnowledge(MemberKnowledge { elders_version: 6, parsec_version: 6 }) }.
TRACE 2020-03-10T11:13:24.341391491+11:00 [/usr/local/cargo/git/checkouts/routing-616e72cf40f12bc0/76713d9/src/states/elder/mod.rs:349] Elder(0a1d37..()) - Received MemberKnowledge { elders_version: 6, parsec_version: 6 } from P2pNode(27a29d.. at 127.0.0.1:4007)
TRACE 2020-03-10T11:13:24.341553236+11:00 [/usr/local/cargo/git/checkouts/routing-616e72cf40f12bc0/76713d9/src/states/common/approved.rs:221] Elder(0a1d37..()) - failed to send parsec request v6 to P2pNode(27a29d.. at 127.0.0.1:4007): Other(UnknownPeer)
TRACE 2020-03-10T11:13:24.382023463+11:00 [/usr/local/cargo/git/checkouts/routing-616e72cf40f12bc0/76713d9/src/states/common/base.rs:230] Elder(0a1d37..()) - try handle message 3d23..9ece
TRACE 2020-03-10T11:13:24.383664372+11:00 [/usr/local/cargo/git/checkouts/routing-616e72cf40f12bc0/76713d9/src/states/elder/mod.rs:714] Elder(0a1d37..()) Got Message { src: Node(PublicId(name: b79f7f..)), dst: Direct, variant: MemberKnowledge(MemberKnowledge { elders_version: 6, parsec_version: 6 }) }.
TRACE 2020-03-10T11:13:24.383781938+11:00 [/usr/local/cargo/git/checkouts/routing-616e72cf40f12bc0/76713d9/src/states/elder/mod.rs:349] Elder(0a1d37..()) - Received MemberKnowledge { elders_version: 6, parsec_version: 6 } from P2pNode(b79f7f.. at 127.0.0.1:4008)
TRACE 2020-03-10T11:13:24.383861741+11:00 [/usr/local/cargo/git/checkouts/routing-616e72cf40f12bc0/76713d9/src/states/common/approved.rs:221] Elder(0a1d37..()) - failed to send parsec request v6 to P2pNode(b79f7f.. at 127.0.0.1:4008): Other(UnknownPeer)
The script I’m using to start these vaults all with trace level logs is
#!/bin/sh
VAULT_BINARY=/home/ian/.safe/vault/safe_vault
LOG_HOME=/tmp/baby-fleming/`date +"%Y-%m-%d_%H-%M"`
STARTUP_DELAY=10 #seconds
# start first vault
PORT=4000
LOG_DIR=$LOG_HOME/vault_$PORT
mkdir -p $LOG_DIR
RUST_LOG=trace $VAULT_BINARY --port=$PORT --root-dir=$LOG_DIR --first > $LOG_DIR/vault.log 2>&1 &
sleep $STARTUP_DELAY
# start more vaults
for PORT in 4001 4002 4003 4004 4005 4006 4007 4008 4009
do
LOG_DIR=$LOG_HOME/vault_$PORT
mkdir -p $LOG_DIR
RUST_LOG=trace $VAULT_BINARY --port=$PORT --hard-coded-contacts='["127.0.0.1:4000"]' --root-dir=$LOG_DIR > $LOG_DIR/vault.log 2>&1 &
sleep $STARTUP_DELAY
done
and kill all vaults with
$ pkill safe_vault
Still haven’t got to looking at uploading files or the cpu/memory issues. Just taking small steps and trying to observe each one as closely as possible. Looks like the network is having trouble getting past 7 vaults.
The last log line for the routing table size says 7, so whatever it is that’s happening with the last vaults it means they’re not being added to the routing table.
Would it be a big deal to increase that timeout - or even (temporarily) make it configureable?
It’s messing with my serenity and it looks like Im going to need an if statement at the end of the version of my batch file
On this occasion, there was no timeout on the actual account creation, but ti failed at the login, I have seen it fail often on the account creation
will try your script and see if I can recreate this error.
EDIT: tomorrow…
That’s reproducible…
and with 20 vaults, the vaults are still running until stopped but logging the like of:
DEBUG 2020-03-10T04:02:45.977808516+00:00 [/usr/local/cargo/registry/src/github.com-1ecc6299db9ec823/quic-p2p-0.4.0/src/
communicate.rs:198] Error in Incoming-bi-stream while reading from peer 127.0.0.1:4003: ApplicationClosed { reason:
ApplicationClose { error_code: 0, reason: b"" } } - closed by peer: 0.
Note: It
would not be allowed even if it didn’t fail as bi-streams are not allowed
and
DEBUG 2020-03-10T04:02:45.978161963+00:00 [/usr/local/cargo/registry/src/github.com-1ecc6299db9ec823/quic-p2p-0.4.0/src/
utils.rs:91] ERROR in communication with peer 127.0.0.1:4006: Connection(ApplicationClosed { reason: ApplicationClose
{ error_code: 0, reason: b"" } }) - Connection lost. Details: Incoming streams failed
I uploaded 2 files: a 1 kB file and a 443 kB file. It took less than 13 seconds.
But when I tried a 4.5 MB file, CPU load and memory went to 100% and the upload timed out. That matches other observations.
> [2020-03-10T11:31:41Z ERROR safe] safe-cli error: [Error] NetDataError - Failed to PUT Sequenced Append Only Data: Error(CoreError(Request has timed out - CoreError::RequestTimeout))
If you are happy with building CLI from master, you can change it here: https://github.com/maidsafe/safe-api/blob/master/safe-api/src/api/constants.rs#L16
We could add support for an env var to override its value, although hopefully we will soon not need it, let’s see
Thanks, I’ll have a shot at that later ![]()
I’ve also noticed that files under 1 MB upload fast and easy, larger files tend to time out. Still I’m impressed by this wee baby ![]() . It can only get bigger and better from here on.
. It can only get bigger and better from here on.
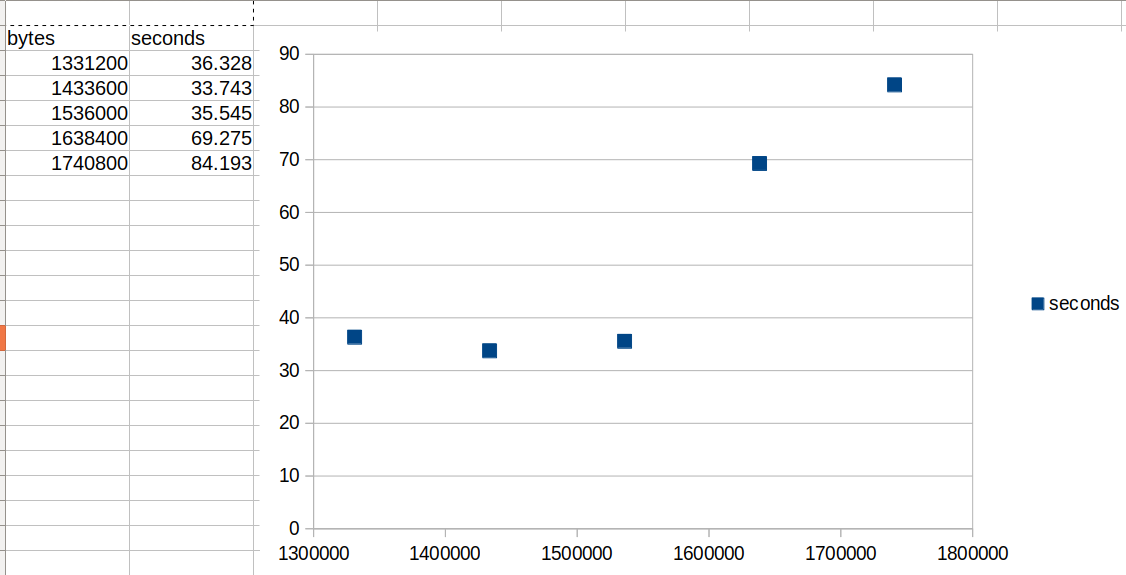
I timed a few runs with increasing payload size. I started at 1.3Mb as I was pretty confident that would work and increased by 100kb until I got a constant 100% load across all cores for >3mins at which point I hit enter on safe vault killall
I ran the commands as follows
willie@sputnik:~/.safe/vault$ dd if=/dev/urandom of=/tmp/rand.dat bs=1k count=1300 1300+0 records in 1300+0 records out 1331200 bytes (1.3 MB, 1.3 MiB) copied, 0.0139337 s, 95.5 MB/s willie@sputnik:~/.safe/vault$ time safe files put /tmp/rand.dat
FilesContainer created at: "safe://hnyynyswt61kfdccp4qj7oci7sha6jwj9h5s8z1ht9igz9yjpbq9ti5xdkbnc"
+ /tmp/rand.dat safe://hbkyyod3p3aoh3spa5zizkae3ycy14fr5d6ik3r5skpwtgzow9q6nfrr6o
real 0m36.328s
user 0m0.351s
sys 0m0.067s
willie@sputnik:~/.safe/vault$
willie@sputnik:~/.safe/vault$ dd if=/dev/urandom of=/tmp/rand.dat bs=1k count=1400
1400+0 records in
1400+0 records out
1433600 bytes (1.4 MB, 1.4 MiB) copied, 0.0126746 s, 113 MB/s
willie@sputnik:~/.safe/vault$ time safe files put /tmp/rand.dat
FilesContainer created at: "safe://hnyynysm8zgudk8zq4a4xy3x433rmmk1eaf4nqih61a1gewgoa34fbcznrbnc"
+ /tmp/rand.dat safe://hbkyyodzpz54ub53jhoyyc5h415cifnigtzj446c1b685ik9cdjpdi6uwm
real 0m33.743s
user 0m0.340s
sys 0m0.072s
willie@sputnik:~/.safe/vault$ dd if=/dev/urandom of=/tmp/rand.dat bs=1k count=1500
1500+0 records in
1500+0 records out
1536000 bytes (1.5 MB, 1.5 MiB) copied, 0.0135521 s, 113 MB/s
willie@sputnik:~/.safe/vault$ time safe files put /tmp/rand.dat
FilesContainer created at: "safe://hnyynyix5anwrddfta757bwp48nawsxxu5miugi9b63nmy6fjg1nk5nj86bnc"
+ /tmp/rand.dat safe://hbkyyoduf1yypow7orcsm8o7p7df673zm63i1pxt16zisuz1dmpgmtrusy
real 0m35.545s
user 0m0.342s
sys 0m0.066s
willie@sputnik:~/.safe/vault$ dd if=/dev/urandom of=/tmp/rand.dat bs=1k count=1600
1600+0 records in
1600+0 records out
1638400 bytes (1.6 MB, 1.6 MiB) copied, 0.0139952 s, 117 MB/s
willie@sputnik:~/.safe/vault$ time safe files put /tmp/rand.dat
FilesContainer created at: "safe://hnyynywxuyzqmmfndceax5zf769fxsz1tfy5qd1ygiroehnt4nc6s94wo1bnc"
+ /tmp/rand.dat safe://hbkyyonskhwqcapp97smyqrxiusyfyk31nfqiyfrkcgnpiupaac3o7h8zd
real 1m9.275s
user 0m0.391s
sys 0m0.099s
willie@sputnik:~/.safe/vault$ dd if=/dev/urandom of=/tmp/rand.dat bs=1k count=1700
1700+0 records in
1700+0 records out
1740800 bytes (1.7 MB, 1.7 MiB) copied, 0.0154566 s, 113 MB/s
willie@sputnik:~/.safe/vault$ time safe files put /tmp/rand.dat
FilesContainer created at: "safe://hnyynyiscoxmptkbc7o6eor66x1ewi8sgmuba1o9ncccsc6wae3besugmwbnc"
+ /tmp/rand.dat safe://hbkyyodc8npk5pw3fuc6b6pqfnh45jp3mmnre8mrxkq7hdd4g9613xa9r9
real 1m24.192s
user 0m0.353s
sys 0m0.107s
willie@sputnik:~/.safe/vault$ dd if=/dev/urandom of=/tmp/rand.dat bs=1k count=1800
1800+0 records in
1800+0 records out
1843200 bytes (1.8 MB, 1.8 MiB) copied, 0.0160186 s, 115 MB/s
willie@sputnik:~/.safe/vault$ time safe files put /tmp/rand.dat
^C
real 3m24.340s
user 0m0.394s
sys 0m0.083s+
So on this 8 core Intel(R) Core™ i7-7700HQ CPU @ 2.80GHz with 16Gb RAM running Ubuntu 18.04, we see that somewhere between 1.7 and 1.8Mb is the largest practical file size that can be put to a “standard” baby-Fleming 8 vault network for the time being.
Just want to say how much I’m loving @southside’s contributions to this thread and the testing.
thats awfy nice of you to say so Shane, but I was going to buy you beer anyway ![]()
I just wanted to show that its not that difficult to do some basic testing and if we can get some more folk submitting their results on a variety of hardware, it may help the devs.
And if it doesn’t , I’m having fun any way…
Red wine helps find errors! ![]()
Following @Southside thought above…
$ dd if=/dev/urandom of=/tmp/rand.dat bs=1k count=1300
1300+0 records in
1300+0 records out
1331200 bytes (1.3 MB, 1.3 MiB) copied, 0.0330399 s, 40.3 MB/s
So, forgetting to start the vaults (yeah, one glass ![]() )
)
I got
$ time ./safe files put /tmp/rand.dat
[2020-03-10T19:52:39Z ERROR safe] safe-cli error: [Error] NetDataError - Failed to PUT Sequenced Append Only Data: Error(CoreError(Operation forbidden - CoreError::OperationForbidden))
real 0m30.250s
user 0m0.236s
sys 0m0.029s
Which I thought odd… because why does it take 30s to note that no vaults are running?
Then running vaults (yes, it’s a good idea)
$ time ./safe files put /tmp/rand.dat
nothing for a loong while… but this deliberate wondering if I’m not logged in / authorised, would it still - as there was a surprise yesterday that account was recalled ok; so, starting not entirely fresh each time, which is nice.
…that manually stopped at
real 4m23.199s
Now, properly
$ ./safe auth login --self-auth
$ time ./safe files put /tmp/rand.dat
Watching the System Monitor, noting CPUs maxed out and RAM rising this is familiar…
This is Intel® Core™ i3-7100U CPU @ 2.40GHz × 4
and 15.5 GiB (why am I missing 0.5GB RAM is a mystery)
CPUs maxed out for most of the time… well beyond just 33s though… and hovering for a good few minutes around 2.8GB having topped at 3GB early on… then slow climb through 3.2GB
I then noticed the console job had stopped… despite the CPUs continuing at 100%. So, odd of course that the files put has stopped but CPUs left busy.
$ time ./safe files put /tmp/rand.dat
[2020-03-10T20:05:31Z ERROR safe] safe-cli error: [Error] NetDataError - **Failed to PUT** Sequenced Append Only Data: Error(CoreError(Request has timed out - CoreError::RequestTimeout))
real **6m0.201s**
user 0m0.441s
sys 0m0.098s
and of course stopping vaults with
$ ./safe vault killall
So, I get **Failed to PUT**
Which seems odd relative to @Southside above getting " FilesContainer created at:
I wonder the only diff is I’m using an i3 for this and above was i7.
and just to test that it is not me… a simple put of small 2.8kb file worked
$ time ./safe files put ./test
FilesContainer created at: "safe://hnyynyw6n84wsqaiocdinranas7stse51b89go6nekjznho47c7dsmgx8sbnc"
+ ./test safe://hbyyyyn5f1uygwjuji9pgn8kaxpi8yk34z6rccc6m9jh7f7mpqec9d6gya
real 0m35.833s
user 0m0.101s
sys 0m0.008s
![]()
Credit where it’s due … That was @mav’s thought - he put me right on using /dev/urandom for a better testing method. Previously I was just grabbing something the right size out of my Downloads folder. So we could have variation on results cos a 1.5Mb .jpeg is processed differentlly from a far more organised 1.7Mb log file for example. I’m sure there is a more correct way of expressing that but I think you know what Im getting at.
Possibly…
can I suggest you try starting at say 800Kb
dd if=/dev/urandom of=/tmp/rand.dat bs=1k count=800
see if you can store that OK. IF yes then make your rand.dat 900k and work up until you get a failure.
If not, step down by 50 or 100k until you can successfully put the file
Why is the network not growing past 7 nodes?
I added a log message just before this call to send_member_knowledge in adult handle_timeout.
The adult handle_timeout function is being called a lot. It calls send_member_knowldege, which is what the 8th vault is doing continuously.
The 1st vault to join sent member knowledge here 0 times (ie the one started with --first flag).
The 2nd vault to join sent member knowledge here 1 times.
The 3rd vault to join sent member knowledge here 2 times.
The 4th vault to join sent member knowledge here 3 times.
The 5th vault to join sent member knowledge here 4 times.
The 5th vault to join sent member knowledge here 4 times.
The 6th vault to join sent member knowledge here 4 times.
The 7th vault to join sent member knowledge here 4 times.
The 8th vault to join sent member knowledge here endlessly.
My suspicion is that the 8th vault (ie the one that forms a full section of elders) is not being promoted from adult to elder correctly.
Looking at the Transition of states from joining to adult to elder (adding a log message to the transition section), it does indeed show the eighth vault not being promoted to elder.
I admit to being caught out here, I expected elders to be 8 but no, it’s 7, see ELDER_SIZE = 7.
So the eigth vault is expected to stay an adult, and that is what is happening.
Also the routing table only shows the number of elders, ie elders().count() source. This caught me by surprise! I was expecting the routing table to count all nodes in the section.
Another surprise in the logging, network size is also reported using elders().count() source. This is very surprising. Adults are not counted in network size. Changing it to network_size = self.elders_and_adults().count() gave me thee result I expected - and showed that all vaults are being joined to the network. I got a network of ten vaults no worries. A lot of unnecessary gossip from adults but that’s a known thing (see the TODO comment in that part of the code).
So the eigth (and more) nodes are actually doing what is expected - not becoming an elder and not being counted in any logged network stats and continuously sending member_knowledge (when it should only send on change). Frustrating but I guess that’s what unfamiliarity with a rapidly changing codebase is all about.
So now the network is known to grow as expected. Next is to look into uploads taking a lot of cpu and memory.
I sense mav is powering up with this codebase. Debug us to freedom mate!
The Freeza… errr I mean bugs are afraid now ![]() .
.
I built the latest CLI from master from source and modified https://github.com/maidsafe/safe-api/blob/master/safe-api/src/api/constants.rs#L16 as suggested by @bochaco. I changed the timeout from 60 secs to 180.
I don’t think that change of mine was relevant as when I run the CLI now the account creation and login processes seem MUCH faster and thus reliable. - Thanks folks ![]()
I only did limited put testing, Times are very much the same as in my previous post this evening I did discover 1.65MB is few Kb too far.
If I have some free time at work tomorrow I’ll try to run the tests again in a more structured manner.
Enough for tonight , time for kip
Nice work everybody, super interesting to follow.
Slightly offtopic: How many replicas of the chunks Baby Fleming is saving?