Console is designed to work with text.
Using it for binary data transfer is a hack.
No surprise that it fails in unpredictable ways.
I hope that binary cat will be eventually replaced with more reliable commands.
Console is designed to work with text.
Using it for binary data transfer is a hack.
No surprise that it fails in unpredictable ways.
I hope that binary cat will be eventually replaced with more reliable commands.
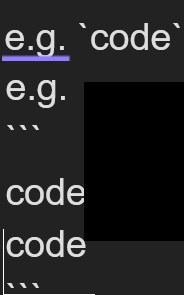
to use code in the forum posts you need to use backticks before and after
`
e.g. code
or triple backticks in the before and after line of code ```
e.g.
code
code
the backtick is under the ESC key on the keyboard
also here you would need to update your instructions,
to get a file you need to prepend safe cat
so in your example:
safe cat safe://hygoygym7tsj5hhyyykd1aqpw3djxea6om6xku568ahm7hy7gfn6q5gy7xr > 1.jpg
there is also another (better IMO) way to download files
by using the container xorurl
safe files get <container-xorurl>
this way you download all data from that container and filenames automaticly too
seems like your upload stoped at the letter b? I imagine you have more mp3s with other first letters too?
so far 1909 mp3 files!
edit: NO! I was wrong! now there are 1961 mp3s in the container! so the upload continues normally but I guess its just a huge collection and it takes time to upload!
I found out how to restart the download with preserving the existing data and downloading only the new!
safe files get -e preserve <container-xorul>
awesome!!!
OK I wont waste any more time on that.
If we get similar reports we can raise an issue if need be.
Or as @Vort says, develop a more suitable tool.
I always have thought of cat as a hacky “internal” tool that would not be directly exposed in the long awaited API.
Just something to use in the early stages for proving to ourselves that it worked. Or didnt…
I think cat would be useful only with downloads as in you click download and it uses cat and you set the filename, but it would need some other tool to get what kind of file it is (extention) like .mp3
Allright, 1.6GB of photos (jpg), 194 photos alltogether put succesfully, not a single error message:
real 46m23,250s
user 5m52,402s
sys 1m51,864s
Thanks once more @Southside for the instructions!
Awesome!
Then you want to keep checking that they are all still there ![]()
Why are some nodes only storing a few K (12K to 24K)?
elders? 20char
Good thought, but it’s only three out of twenty. The rest are storing GB ![]()
GET ting the whole container:
real 4m23,231s
user 1m0,919s
sys 0m24,324s
That was quick in my opinion. No error messages. I opened a couple images randomly, no problems.
Ok, so there’s some benefit in trying to get them a few times in a day for example?
How much space there is left in the nodes? Should we try to fill them up?
Yes the logs will be interesting. Perhaps some nodes were adults then promoted, but most likely, they started storing while the network was loading, and with no adults they stored the data. Anyway we need to analyse these logs and update everyone with the results.
Then we move on to the next test. We want to push into DBCs and then, after that have to pay for uploads (interesting problem) and so on.
Nodes form home is likely where there are silly comms bugs and that testnet will be interesting, but we are doing a lot of work in coms in parallel so that it may pull together at the right time. At least then all we are testing is comms and nodes from home.
More interesting than making decentralization actually work?
I propose intermediate step:
Nodes are still centralized, but randomly goes offline and online.
Part of making decentralization actually work?
Yes that makes sense, but not so easy to do. We can give it some thought. The issue will be when it’s open people will add nodes we don’t know and then the usual off/on/off/on stuff happens which is harder to analyse when we cannot get all the logs.
I think the idea is that nodes from home is the most complex and difficult test to debug, so best to test as many of the other simpler to fix features first and do the hardest tests last to make them easier.
In long run, yes.
But network usually fails earlier than people overflow it with data.
That’s why I said “centralized”.
I mean that nodes under your full control.
But sometimes they leave and join later.
It will on one side simulate somehow decentralized behaviour and on other side it will allow to track 100% of events.
Absolutely. Lets get the simple(r) components rock solid and build slowly on top.
Yep! The first occurrence of someone not being able to get what they once uploaded, is what we are keeping an eye out for now.
And we can always run Comnets in parallel to official ones.